
$ cnpm install cspell
cspell
![]()
![]()
![]()
A Spell Checker for Code!
cspell is a command line tool and library for spell checking code.
Support Future Development
- Become a
 Patreon!
Patreon!
Features
- Spell Checks Code -- Able to spell check code by parsing it into words before checking against the dictionaries.
- Supports CamelCase, snake_case, and compoundwords naming styles.
- Self contained -- does not depend upon OS libraries like Hunspell or aspell. Nor does it depend upon online services.
- Fast -- checks 1000's of lines of code in seconds.
- Programming Language Specific Dictionaries -- Has dedicated support for:
- JavaScript, TypeScript, Python, PHP, C#, C++, LaTex, Go, HTML, CSS, etc.
- Customizable -- supports custom dictionaries and word lists.
- Continuous Integration Support -- Can easily be added as a linter to Travis-CI.
cspell was initially built as the spell checking service for the spell checker extension for Visual Studio Code.
cspell for enterprise
Available as part of the Tidelift Subscription.
The maintainers of cspell and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source packages you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact packages you use. Learn more.
Installation
npm install -g cspell
Basic Usage
Example: recursively spell check all JavaScript files in src
JavaScript files
cspell "src/**/*.js"
# or
cspell lint "src/**/*.js"
Check everything
cspell "**"
Git: Check Only Changed Files
git diff --name-only | npx cspell --file-list stdin
Command: lint -- Spell Checking
The lint command is used for spell checking files.
Help
cspell lint --help
Options
Usage: cspell lint [options] [globs...]
Check spelling
Options:
-c, --config <cspell.json> Configuration file to use. By default cspell
looks for cspell.json in the current directory.
-v, --verbose Display more information about the files being
checked and the configuration.
--locale <locale> Set language locales. i.e. "en,fr" for English
and French, or "en-GB" for British English.
--language-id <language> Force programming language for unknown
extensions. i.e. "php" or "scala"
--words-only Only output the words not found in the
dictionaries.
-u, --unique Only output the first instance of a word not
found in the dictionaries.
-e, --exclude <glob> Exclude files matching the glob pattern. This
option can be used multiple times to add
multiple globs.
--file-list <path or stdin> Specify a list of files to be spell checked. The
list is filtered against the glob file patterns.
Note: the format is 1 file path per line.
--no-issues Do not show the spelling errors.
--no-progress Turn off progress messages
--no-summary Turn off summary message in console.
-s, --silent Silent mode, suppress error messages.
-r, --root <root folder> Root directory, defaults to current directory.
--relative Issues are displayed relative to root.
--show-context Show the surrounding text around an issue.
--show-suggestions Show spelling suggestions.
--no-must-find-files Do not error if no files are found.
--cache Use cache to only check changed files.
--no-cache Do not use cache.
--cache-strategy <strategy> Strategy to use for detecting changed files.
(choices: "metadata", "content")
--cache-location <path> Path to the cache file or directory. (default:
".cspellcache")
--dot Include files and directories starting with `.`
(period) when matching globs.
--gitignore Ignore files matching glob patterns found in
.gitignore files.
--no-gitignore Do NOT use .gitignore files.
--gitignore-root <path> Prevent searching for .gitignore files past
root.
--no-color Turn off color.
--color Force color.
--debug Output information useful for debugging
cspell.json files.
-h, --help display help for command
Examples:
cspell "*.js" Check all .js files in the current directory
cspell "**/*.js" Check all .js files from the current directory
cspell "src/**/*.js" Only check .js under src
cspell "**/*.txt" "**/*.js" Check both .js and .txt files.
cspell "**/*.{txt,js,md}" Check .txt, .js, and .md files.
cat LICENSE | cspell stdin Check stdin
Command: check - Quick Visual Check
Do a quick visual check of a file. This is a great way to see which text is included in the check.
cspell check <filename>
It will produce something like this:
Tip for use with less
To get color in less, use --color and less -r
cspell check <filename> --color | less -r
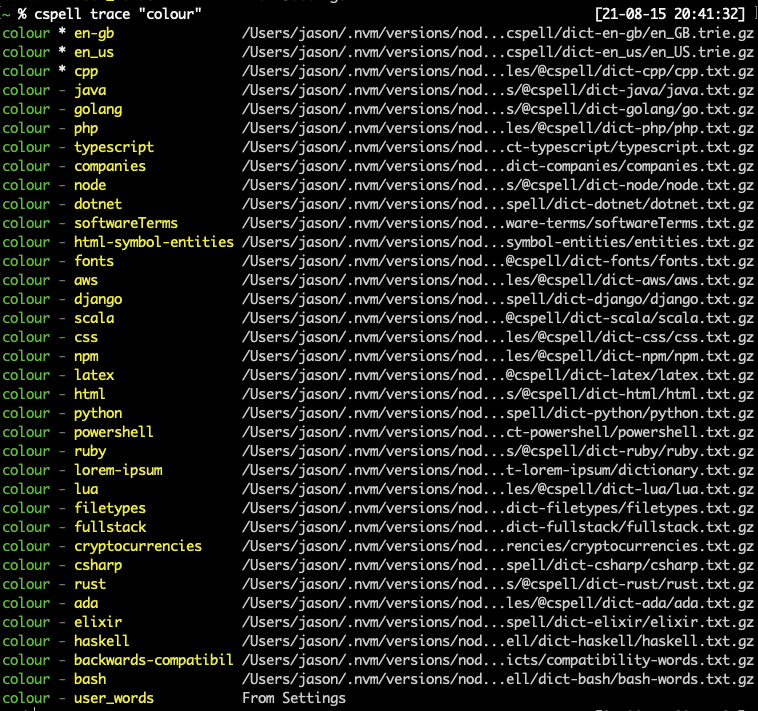
Command: trace - See which dictionaries contain a word
Trace shows a the list of known dictionaries and a * next to the ones that contain the word.
A ! will appear next to the ones where the word is forbidden.
CI/CD Continuous Integration support
Mega-Linter
Mega-Linter aggregates 70 linters ready to use out of the box, including cspell
- Can run as a GitHub Action, on other CI tools and locally
- Provides an updated
.cspell.jsonfile with new unknown words
Setup
Quick setup following installation guide in Mega-Linter documentation
Git commit-hooks
pre-commit
Setup
npm install -SD cspell
.git/hooks/pre-commit
#!/bin/sh
exec git diff --cached --name-only | npx cspell -- --no-summary --no-progress --no-must-find-files --file-list stdin
Requirements
cspell needs Node 12 and above.
How it works
The concept is simple, split camelCase and snake_case words before checking them against a list of known words.
camelCase->camel caseHTMLInput->html inputsrcCode->src codesnake_case_words->snake case wordscamel2snake->camel snake-- (the 2 is ignored)function parseJson(text: string)->function parse json text string
Special cases
- Escape characters like
\n,\tare removed if the word does not match:\narrow->narrow- becausenarrowis a word\ncode->code- becausencodeis not a word.\network->network- but it might be hiding a spelling error, if\nwas an escape character.
Things to note
- This spellchecker is case insensitive. It will not catch errors like
englishwhich should beEnglish. - The spellchecker uses dictionaries stored locally. It does not send anything outside your machine.
- The words in the dictionaries can and do contain errors.
- There are missing words.
- Only words longer than 3 characters are checked. "jsj" is ok, while "jsja" is not.
- All symbols and punctuation are ignored.
In Document Settings
It is possible to add spell check settings into your source code. This is to help with file specific issues that may not be applicable to the entire project.
All settings are prefixed with cSpell: or spell-checker:.
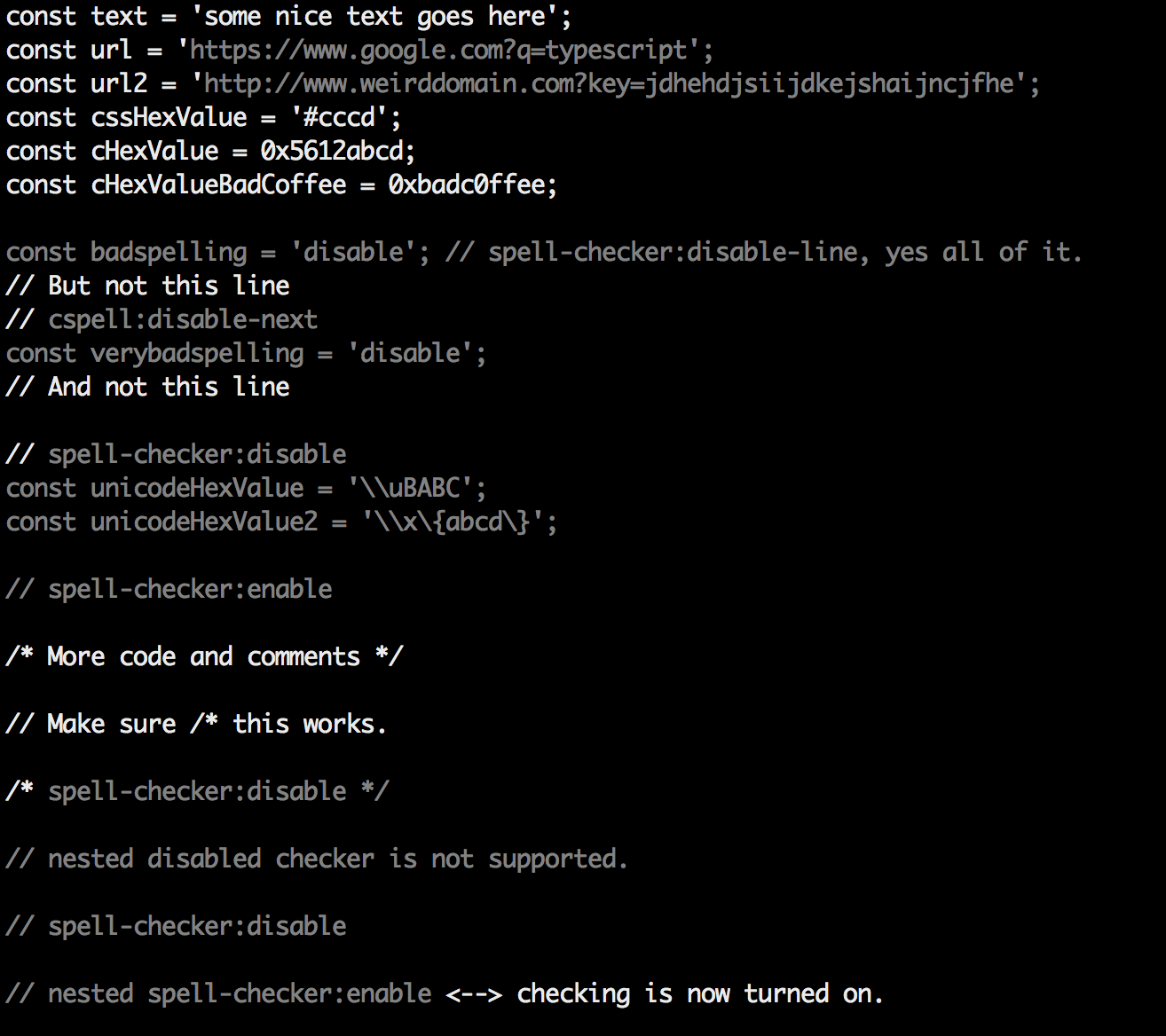
disable-- turn off the spell checker for a section of code.enable-- turn the spell checker back on after it has been turned off.ignore-- specify a list of words to be ignored.words-- specify a list of words to be considered correct and will appear in the suggestions list.ignoreRegExp-- Any text matching the regular expression will NOT be checked for spelling.includeRegExp-- Only text matching the collection of includeRegExp will be checked.enableCompoundWords/disableCompoundWords-- Allow / disallow words like: "stringlength".dictionaries-- specify a list of the names of the dictionaries to use.
Enable / Disable checking sections of code
It is possible to disable / enable the spell checker by adding comments to your code.
Disable Checking
/* cSpell:disable *//* spell-checker: disable *//* spellchecker: disable */// cspell:disable-line-- disables checking for the current line./* cspell:disable-next-line */-- disables checking till the end of the next line.
Enable Checking
/* cSpell:enable *//* spell-checker: enable *//* spellchecker: enable */
Example
// cSpell:disable
const wackyWord = ['zaallano', 'wooorrdd', 'zzooommmmmmmm'];
/* cSpell:enable */
const words = ['zaallano', 'wooorrdd', 'zzooommmmmmmm']; // cspell:disable-line disables this entire line
// To disable the next line, use cspell:disable-next-line
const moreWords = ['ieeees', 'beees', 'treeees'];
// Nesting disable / enable is not Supported
// spell-checker:disable
// It is now disabled.
var liep = 1;
/* cspell:disable */
// It is still disabled
// cSpell:enable
// It is now enabled
const str = 'goededag'; // <- will be flagged as an error.
// spell-checker:enable <- doesn't do anything
// cSPELL:DISABLE <-- also works.
// if there isn't an enable, spelling is disabled till the end of the file.
const str = 'goedemorgen'; // <- will NOT be flagged as an error.
Ignore
Ignore allows you the specify a list of words you want to ignore within the document.
// cSpell:ignore zaallano, wooorrdd
// cSpell:ignore zzooommmmmmmm
const wackyWord = ['zaallano', 'wooorrdd', 'zzooommmmmmmm'];
Note: words defined with ignore will be ignored for the entire file.
Words
The words list allows you to add words that will be considered correct and will be used as suggestions.
// cSpell:words woorxs sweeetbeat
const companyName = 'woorxs sweeetbeat';
Note: words defined with words will be used for the entire file.
Enable / Disable compound words
In some programing language it is common to glue words together.
// cSpell:enableCompoundWords
char * errormessage; // Is ok with cSpell:enableCompoundWords
int errornumber; // Is also ok.
Note: Compound word checking cannot be turned on / off in the same file. The last setting in the file determines the value for the entire file.
Excluding and Including Text to be checked.
By default, the entire document is checked for spelling.
cSpell:disable/cSpell:enable above allows you to block off sections of the document.
ignoreRegExp and includeRegExp give you the ability to ignore or include patterns of text.
By default the flags gim are added if no flags are given.
The spell checker works in the following way:
- Find all text matching
includeRegExp - Remove any text matching
ignoreRegExp - Check the remaining text.
Exclude Example
// cSpell:ignoreRegExp 0x[0-9a-f]+ -- will ignore c style hex numbers
// cSpell:ignoreRegExp /0x[0-9A-F]+/g -- will ignore upper case c style hex numbers.
// cSpell:ignoreRegExp g{5} h{5} -- will only match ggggg, but not hhhhh or 'ggggg hhhhh'
// cSpell:ignoreRegExp g{5}|h{5} -- will match both ggggg and hhhhh
// cSpell:ignoreRegExp /g{5} h{5}/ -- will match 'ggggg hhhhh'
/* cSpell:ignoreRegExp /n{5}/ -- will NOT work as expected because of the ending comment -> */
/*
cSpell:ignoreRegExp /q{5}/ -- will match qqqqq just fine but NOT QQQQQ
*/
// cSpell:ignoreRegExp /[^\s]{40,}/ -- will ignore long strings with no spaces.
// cSpell:ignoreRegExp Email -- this will ignore email like patterns -- see Predefined RegExp expressions
var encodedImage = 'HR+cPzr7XGAOJNurPL0G8I2kU0UhKcqFssoKvFTR7z0T3VJfK37vS025uKroHfJ9nA6WWbHZ/ASn...';
var email1 = 'emailaddress@myfancynewcompany.com';
var email2 = '<emailaddress@myfancynewcompany.com>';
Note: ignoreRegExp and includeRegExp are applied to the entire file. They do not start and stop.
Include Example
In general you should not need to use includeRegExp. But if you are mixing languages then it could come in helpful.
# cSpell:includeRegExp #.*
# cSpell:includeRegExp ("""|''')[^\1]*\1
# only comments and block strings will be checked for spelling.
def sum_it(self, seq):
"""This is checked for spelling"""
variabele = 0
alinea = 'this is not checked'
for num in seq:
# The local state of 'value' will be retained between iterations
variabele += num
yield variabele
Dictionaries
The dictionaries list allows you to specify dictionaries to use for the file.
// cSpell:dictionaries lorem-ipsum
const companyName = 'Lorem ipsum dolor sit amet';
Note: dictionaries specified with dictionaries will be used for the entire file.
Predefined RegExp expressions
Exclude patterns
Urls1 -- Matches urlsHexValues-- Matches common hex format like #aaa, 0xfeef, \u0134Base641 -- matches base64 blocks of text longer than 40 characters.Email-- matches most email addresses.
Include Patterns
Everything1 -- By default we match an entire document and remove the excludes.string-- This matches common string formats like '...', "...", and `...`CStyleComment-- These are C Style comments /* */ and //PhpHereDoc-- This matches PHPHereDoc strings.
1. These patterns are part of the default include/exclude list for every file.
Customization
cspell's behavior can be controlled through a config file. By default it looks for any of the following files:
.cspell.jsoncspell.json.cSpell.jsoncSpell.jsoncspell.config.jscspell.config.cjscspell.config.jsoncspell.config.yamlcspell.config.ymlcspell.yamlcspell.yml
Or you can specify a path to a config file with the --config <path> argument on the command line.
cspell.json
Example cspell.json file
// cSpell Settings
{
// Version of the setting file. Always 0.2
"version": "0.2",
// language - current active spelling language
"language": "en",
// words - list of words to be always considered correct
"words": [
"mkdirp",
"tsmerge",
"githubusercontent",
"streetsidesoftware",
"vsmarketplacebadge",
"visualstudio"
],
// flagWords - list of words to be always considered incorrect
// This is useful for offensive words and common spelling errors.
// For example "hte" should be "the"
"flagWords": [
"hte"
]
}
cspell.json sections
-
version- currently always 0.2 - controls how the settings in the configuration file behave. -
language- this specifies the language locale to use in choosing the general dictionary. For example:"language": "en-GB"tells cspell to use British English instead of US English. -
words- a list of words to be considered correct. -
flagWords- a list of words to be always considered incorrect -
ignoreWords- a list of words to be ignored (even if they are in the flagWords). -
ignorePaths- a list of globs to specify which files are to be ignored.Example
"ignorePaths": ["node_modules/**"]will cause cspell to ignore anything in the
node_modulesdirectory. -
maxNumberOfProblems- defaults to 100 per file. -
minWordLength- defaults to 4 - the minimum length of a word before it is checked. -
allowCompoundWords- defaults to false; set to true to allow compound words by default. -
dictionaries- list of the names of the dictionaries to use. See Dictionaries below. -
dictionaryDefinitions- this list defines any custom dictionaries to use. This is how you can include other languages like Spanish.Example
"language": "en", // Dictionaries "spanish", "ruby", and "corp-term" will always be checked. // Including "spanish" in the list of dictionaries means both Spanish and English // words will be considered correct. "dictionaries": ["spanish", "ruby", "corp-terms", "fonts"], // Define each dictionary. Relative paths are relative to the config file. "dictionaryDefinitions": [ { "name": "spanish", "path": "./spanish-words.txt"}, { "name": "ruby", "path": "./ruby.txt"}, { "name": "company-terms", "path": "./corp-terms.txt"} ], -
ignoreRegExpList- list of patterns to be ignored -
includeRegExpList- (Advanced) limits the text checked to be only that matching the expressions in the list. -
patterns- this allows you to define named patterns to be used withignoreRegExpListandincludeRegExpList. -
languageSettings- this allow for per programming language configuration settings. See LanguageSettings
Dictionaries
The spell checker includes a set of default dictionaries.
General Dictionaries
- en_US - Derived from Hunspell US English words.
- en-gb - Derived from Hunspell GB English words.
- companies - List of well known companies
- softwareTerms - Software Terms and concepts like "coroutine", "debounce", "tree", etc.
- misc - Terms that do not belong in the other dictionaries.
Programming Language Dictionaries
- typescript - keywords for TypeScript and JavaScript
- node - terms related to using nodejs.
- php - php keywords and library methods
- go - go keywords and library methods
- python - python keywords
- powershell - powershell keywords
- html - html related keywords
- css - css, less, and scss related keywords
- cpp - C++ related keywords
- csharp - C# related keywords
- latex - LaTex related words
- bash - Bash/shell script keywords
Miscellaneous Dictionaries
- fonts - long list of fonts - to assist with css
- filetypes - list of file typescript
- npm - list of top 500+ package names on npm.
Dictionary Definition
- name - The reference name of the dictionary, used with program language settings
- description - Optional description
- path - Path to the file, can be relative or absolute. Relative path is relative to the
current
cspell.jsonfile. - repMap - Optional replacement map use to replace character prior to searching the dictionary.
Example:
// Use Compounds// Replace various tick marks with a single ' "repMap": [["'|`|’", "'"]] - useCompounds - allow compound words
// Define each dictionary. Relative paths are relative to the config file.
"dictionaryDefinitions": [
{ "name": "spanish", "path": "./spanish-words.txt"},
{ "name": "ruby", "path": "./ruby.txt"},
{ "name": "company-terms", "path": "./corp-terms.txt"}
],
Disabling a Dictionary
It is possible to prevent a dictionary from being loaded. This is useful if you want to use your own dictionary or just turn off an existing dictionary.
Disable Default cpp Dictionary
"dictionaries": ["!cpp"],
"overrides": [
{
"filename": "legacy/**/*.cpp",
"dictionaries": ["!!cpp"], // add it back for *.cpp files under the legacy folder
},
]
The number of !s is important.
!cppremovecppdictionary!!cppadd it back!!!cppremove it again.
LanguageSettings
The Language Settings allow configuration to be based upon the programming language and/or the e.
There are two selector fields locale and languageId.
languageIddefines which programming languages to match against. A value of"python,javascript"will match against python and javascript files. To match against ALL programming languages, use"*".localedefines which spoken languages to match against. A value of"en-GB,nl"will match against British English or Dutch. A value of"*"will match all spoken languages.- Most configuration values allowed in a
cspell.jsonfile can be define or redefine within thelanguageSettings.
"languageSettings": [
{
// VSCode languageId. i.e. typescript, java, go, cpp, javascript, markdown, latex
// * will match against any file type.
"languageId": "c,cpp",
// Language locale. i.e. en-US, de-AT, or ru. * will match all locales.
// Multiple locales can be specified like: "en, en-US" to match both English and English US.
"locale": "*",
// To exclude patterns, add them to "ignoreRegExpList"
"ignoreRegExpList": [
"/#include.*/"
],
// List of dictionaries to enable by name in `dictionaryDefinitions`
"dictionaries": ["cpp"],
// Dictionary definitions can also be supplied here. They are only used iff "languageId" and "locale" match.
"dictionaryDefinitions": []
}
]
Overrides
Overrides are useful for forcing configuration on a per file basis.
Example:
"overrides": [
// Force `*.hrr` and `*.crr` files to be treated as `cpp` files:
{
"filename": "**/{*.hrr,*.crr}",
"languageId": "cpp"
},
// Force `*.txt` to use the Dutch dictionary (Dutch dictionary needs to be installed separately):
{
"language": "nl",
"filename": "**/dutch/**/*.txt"
}
]
Current Tags
- 4.2.8 ... cspell4 (5 years ago)
- 5.17.0 ... latest (4 years ago)
- 5.17.0-alpha.0 ... next (4 years ago)
254 Versions
- 5.17.0 ... 4 years ago
- 5.17.0-alpha.0 ... 4 years ago
- 5.16.0 ... 4 years ago
- 5.15.3 ... 4 years ago
- 5.15.2 ... 4 years ago
- 5.15.1 ... 4 years ago
- 5.15.0 ... 4 years ago
- 5.14.0 ... 4 years ago
- 5.14.0-alpha.0 ... 4 years ago
- 5.13.4 ... 4 years ago
- 5.13.3 ... 4 years ago
- 5.13.2 ... 4 years ago
- 5.13.1 ... 4 years ago
- 5.13.0 ... 4 years ago
- 5.12.6 ... 4 years ago
- 5.12.5 ... 4 years ago
- 5.12.4 ... 4 years ago
- 5.12.3 ... 5 years ago
- 5.12.2 ... 5 years ago
- 5.12.1 ... 5 years ago
- 5.12.0 ... 5 years ago
- 5.12.0-alpha.0 ... 5 years ago
- 5.11.1 ... 5 years ago
- 5.11.0 ... 5 years ago
- 5.11.0-alpha.0 ... 5 years ago
- 5.10.1 ... 5 years ago
- 5.10.0 ... 5 years ago
- 5.10.0-alpha.6 ... 5 years ago
- 5.10.0-alpha.5 ... 5 years ago
- 5.10.0-alpha.4 ... 5 years ago
- 5.10.0-alpha.3 ... 5 years ago
- 5.10.0-alpha.2 ... 5 years ago
- 5.9.1 ... 5 years ago
- 5.9.1-alpha.1 ... 5 years ago
- 5.9.0 ... 5 years ago
- 5.9.0-alpha.0 ... 5 years ago
- 5.8.2 ... 5 years ago
- 5.8.1 ... 5 years ago
- 5.8.0 ... 5 years ago
- 5.7.2 ... 5 years ago
- 5.7.1 ... 5 years ago
- 5.7.0 ... 5 years ago
- 5.7.0-alpha.0 ... 5 years ago
- 5.6.7 ... 5 years ago
- 5.6.6 ... 5 years ago
- 5.6.5 ... 5 years ago
- 5.6.4 ... 5 years ago
- 5.6.3 ... 5 years ago
- 5.6.2 ... 5 years ago
- 5.6.1 ... 5 years ago
- 5.6.0 ... 5 years ago
- 5.5.2 ... 5 years ago
- 5.5.1 ... 5 years ago
- 5.5.0 ... 5 years ago
- 5.4.1 ... 5 years ago
- 5.4.0 ... 5 years ago
- 5.3.12 ... 5 years ago
- 5.3.11 ... 5 years ago
- 5.3.10 ... 5 years ago
- 5.3.9 ... 5 years ago
- 5.3.8 ... 5 years ago
- 5.3.7 ... 5 years ago
- 5.3.7-alpha.3 ... 5 years ago
- 5.3.7-alpha.2 ... 5 years ago
- 5.3.7-alpha.1 ... 5 years ago
- 5.3.7-alpha.0 ... 5 years ago
- 5.3.6 ... 5 years ago
- 5.3.5 ... 5 years ago
- 5.3.4 ... 5 years ago
- 5.3.3 ... 5 years ago
- 5.3.2 ... 5 years ago
- 5.3.1 ... 5 years ago
- 5.3.0 ... 5 years ago
- 5.3.0-alpha.4 ... 5 years ago
- 5.3.0-alpha.3 ... 5 years ago
- 5.3.0-alpha.2 ... 5 years ago
- 5.3.0-alpha.1 ... 5 years ago
- 5.3.0-alpha.0 ... 5 years ago
- 5.2.4 ... 5 years ago
- 5.2.3 ... 5 years ago
- 5.2.2 ... 5 years ago
- 5.2.1 ... 5 years ago
- 4.2.8 ... 5 years ago
- 5.2.0 ... 5 years ago
- 5.1.3 ... 5 years ago
- 5.1.2 ... 5 years ago
- 5.1.1 ... 5 years ago
- 4.2.7 ... 5 years ago
- 5.1.0 ... 5 years ago
- 5.0.8 ... 5 years ago
- 5.0.7 ... 5 years ago
- 5.0.6 ... 5 years ago
- 5.0.5 ... 5 years ago
- 4.2.6 ... 5 years ago
- 5.0.4 ... 5 years ago
- 5.0.3 ... 5 years ago
- 4.2.5 ... 5 years ago
- 4.2.4 ... 5 years ago
- 4.2.3 ... 5 years ago
- 5.0.2 ... 5 years ago
- 5.0.1 ... 5 years ago
- 5.0.1-alpha.15 ... 5 years ago
- 4.2.2 ... 5 years ago
- 5.0.1-alpha.13 ... 5 years ago
- 4.2.0 ... 5 years ago
- 5.0.1-alpha.12 ... 5 years ago
- 4.1.5 ... 5 years ago
- 4.1.4 ... 5 years ago
- 5.0.1-alpha.11 ... 5 years ago
- 5.0.1-alpha.10 ... 5 years ago
- 5.0.1-alpha.8 ... 5 years ago
- 4.1.3 ... 5 years ago
- 4.1.2 ... 5 years ago
- 5.0.1-alpha.7 ... 5 years ago
- 4.1.1 ... 5 years ago
- 5.0.1-alpha.6 ... 5 years ago
- 4.1.0 ... 6 years ago
- 5.0.1-alpha.5 ... 6 years ago
- 4.0.63 ... 6 years ago
- 4.0.62 ... 6 years ago
- 4.0.61 ... 6 years ago
- 4.0.60 ... 6 years ago
- 4.0.59 ... 6 years ago
- 4.0.58 ... 6 years ago
- 4.0.57 ... 6 years ago
- 5.0.1-alpha.4 ... 6 years ago
- 5.0.1-alpha.3 ... 6 years ago
- 4.0.56 ... 6 years ago
- 4.0.55 ... 6 years ago
- 4.0.54 ... 6 years ago
- 4.0.53 ... 6 years ago
- 4.0.52 ... 6 years ago
- 4.0.51 ... 6 years ago
- 4.0.50 ... 6 years ago
- 4.0.49 ... 6 years ago
- 4.0.48 ... 6 years ago
- 4.0.47 ... 6 years ago
- 4.0.46 ... 6 years ago
- 4.0.44 ... 6 years ago
- 4.0.43 ... 6 years ago
- 4.0.42 ... 6 years ago
- 4.0.41 ... 6 years ago
- 4.0.40 ... 6 years ago
- 4.0.38 ... 6 years ago
- 4.0.37 ... 6 years ago
- 4.0.36 ... 6 years ago
- 4.0.35 ... 6 years ago
- 4.0.34 ... 6 years ago
- 4.0.33 ... 6 years ago
- 4.0.32 ... 6 years ago
- 4.0.31 ... 6 years ago
- 4.0.30 ... 7 years ago
- 4.0.29 ... 7 years ago
- 4.0.28 ... 7 years ago
- 4.0.27 ... 7 years ago
- 4.0.26 ... 7 years ago
- 4.0.25 ... 7 years ago
- 4.0.24 ... 7 years ago
- 4.0.23 ... 7 years ago
- 4.0.21 ... 7 years ago
- 4.0.20 ... 7 years ago
- 4.0.19 ... 7 years ago
- 4.0.18 ... 7 years ago
- 4.0.17 ... 7 years ago
- 4.0.16 ... 7 years ago
- 4.0.15 ... 7 years ago
- 4.0.14 ... 7 years ago
- 4.0.13 ... 7 years ago
- 4.0.12 ... 7 years ago
- 4.0.11 ... 7 years ago
- 4.0.9 ... 7 years ago
- 4.0.8 ... 7 years ago
- 4.0.7 ... 7 years ago
- 4.0.6 ... 7 years ago
- 4.0.5 ... 7 years ago
- 4.0.4 ... 7 years ago
- 4.0.3 ... 7 years ago
- 3.2.17 ... 7 years ago
- 3.2.16 ... 7 years ago
- 3.2.15 ... 7 years ago
- 3.2.14 ... 7 years ago
- 3.2.13 ... 7 years ago
- 3.2.12 ... 7 years ago
- 3.2.11 ... 7 years ago
- 3.2.10 ... 7 years ago
- 3.2.8 ... 7 years ago
- 3.2.6 ... 7 years ago
- 3.2.5 ... 7 years ago
- 3.2.4 ... 7 years ago
- 3.2.2 ... 7 years ago
- 3.2.1 ... 7 years ago
- 3.1.3 ... 8 years ago
- 3.1.2 ... 8 years ago
- 3.1.1 ... 8 years ago
- 3.1.0 ... 8 years ago
- 3.0.2 ... 8 years ago
- 3.0.1 ... 8 years ago
- 2.1.12 ... 8 years ago
- 2.1.11 ... 8 years ago
- 2.1.10 ... 8 years ago
- 2.1.9 ... 8 years ago
- 2.1.8 ... 8 years ago
- 2.1.7 ... 8 years ago
- 2.1.6 ... 8 years ago
- 2.1.5 ... 8 years ago
- 2.1.3 ... 8 years ago
- 2.1.1 ... 8 years ago
- 2.1.0 ... 8 years ago
- 2.0.9 ... 8 years ago
- 2.0.8 ... 8 years ago
- 2.0.6 ... 8 years ago
- 2.0.5 ... 8 years ago
- 2.0.4 ... 8 years ago
- 2.0.3 ... 8 years ago
- 2.0.2 ... 8 years ago
- 2.0.1 ... 8 years ago
- 1.10.6 ... 8 years ago
- 1.10.5 ... 8 years ago
- 1.10.4 ... 9 years ago
- 1.10.3 ... 9 years ago
- 1.10.2 ... 9 years ago
- 1.10.1 ... 9 years ago
- 1.10.0 ... 9 years ago
- 1.9.8 ... 9 years ago
- 1.9.7 ... 9 years ago
- 1.9.6 ... 9 years ago
- 1.9.5 ... 9 years ago
- 1.9.3 ... 9 years ago
- 1.9.2 ... 9 years ago
- 1.8.1 ... 9 years ago
- 1.8.0 ... 9 years ago
- 1.7.4 ... 9 years ago
- 1.7.3 ... 9 years ago
- 1.7.2 ... 9 years ago
- 1.7.1 ... 9 years ago
- 1.7.0 ... 9 years ago
- 1.6.1 ... 9 years ago
- 1.6.0 ... 9 years ago
- 1.5.0 ... 9 years ago
- 1.4.0 ... 9 years ago
- 1.3.3 ... 9 years ago
- 1.3.1 ... 9 years ago
- 1.3.0 ... 9 years ago
- 1.2.1 ... 9 years ago
- 1.2.0 ... 9 years ago
- 1.1.0 ... 9 years ago
- 1.0.8 ... 9 years ago
- 1.0.7 ... 9 years ago
- 1.0.6 ... 9 years ago
- 1.0.5 ... 9 years ago
- 1.0.4 ... 9 years ago
- 1.0.2 ... 9 years ago
- 1.0.1 ... 9 years ago
- 1.0.0 ... 9 years ago
 jason-dent
jason-dent
- chalk ^4.1.2
- commander ^8.3.0
- comment-json ^4.1.1
- cspell-gitignore ^5.17.0
- cspell-glob ^5.17.0
- cspell-lib ^5.17.0
- fast-json-stable-stringify ^2.1.0
- file-entry-cache ^6.0.1
- fs-extra ^10.0.0
- get-stdin ^8.0.0
- glob ^7.2.0
- imurmurhash ^0.1.4
- semver ^7.3.5
- strip-ansi ^6.0.1
- vscode-uri ^3.0.3
- @cspell/cspell-json-reporter ^5.17.0
- @cspell/cspell-types ^5.17.0
- @types/file-entry-cache ^5.0.2
- @types/fs-extra ^9.0.13
- @types/glob ^7.2.0
- @types/imurmurhash ^0.1.1
- @types/micromatch ^4.0.2
- @types/minimatch ^3.0.5
- @types/semver ^7.3.9
- jest ^27.4.7
- micromatch ^4.0.4
- minimatch ^3.0.4
- rimraf ^3.0.2
- rollup ^2.66.1
- rollup-plugin-dts ^4.1.0